UPDATE: A newer blog post explaining the new ggplot2 additions: http://rud.is/b/2016/03/16/supreme-annotations/
UPDATE: this capability (+ more) are being rolled into ggplot2-proper. PR will be absorbed into ggplot2 main branch soon. exciting, annotated times ahead!
UPDATE:
fontsizeissue has been fixed & there’s a Shiny gadget available for interactively making subtitles. More info at the end of the post.
Subtitles aren’t always necessary for plots, but I began to use them enough that I whipped up a function for ggplot2 that does a decent job adding a subtitle to a finished plot object. More than a few folks have tried their hand at this in the past and this is just my incremental contribution until there’s proper support in ggplot2 (someone’s bound to add it via PR at some point).
We’ll nigh fully recreate the following plot from this WaPo article:

Here’s a stab at that w/o the subtitle:
library(ggplot2) library(scales) data.frame( yrs=c("1789-90", "1849-50", "1909-10", "1965-66", "2016-16"), pct=c(0.526, 0.795, 0.713, 0.575, 0.365), xtralabs=c("", "Highest:\n", "", "", "Lowest:\n") ) -> hill_lawyers gg <- ggplot(hill_lawyers, aes(yrs, pct)) gg <- gg + geom_bar(stat="identity", width=0.65) gg <- gg + geom_label(aes(label=sprintf("%s%s", xtralabs, percent(pct))), vjust=-0.4, family=c(rep("FranklinGothic-Book", 4),"FranklinGothic-Heavy"), lineheight=0.9, size=4, label.size=0) gg <- gg + scale_x_discrete() gg <- gg + scale_y_continuous(expand=c(0,0), limits=c(0.0, 1.0), labels=percent) gg <- gg + labs(x=NULL, y=NULL, title="Fewer and fewer lawyers on the Hill") gg <- gg + theme_minimal(base_family="FranklinGothic-Book") gg <- gg + theme(axis.line=element_line(color="#2b2b2b", size=0.5)) gg <- gg + theme(axis.line.y=element_blank()) gg <- gg + theme(axis.text.x=element_text(family=c(rep("FranklinGothic-Book", 4), "FranklinGothic-Heavy"))) gg <- gg + theme(panel.grid.major.x=element_blank()) gg <- gg + theme(panel.grid.major.y=element_line(color="#b2b2b2", size=0.1)) gg <- gg + theme(panel.grid.minor.y=element_blank()) gg <- gg + theme(plot.title=element_text(hjust=0, family="FranklinGothic-Heavy", margin=margin(b=10))) gg

(There are some “tricks” in that plotting code that may be worth spending an extra minute or two to mull over if you didn’t realize some of the function parameters were vectorized, or that you could get a white background with no border for text labels so grid lines don’t get in the way.)
Ideally, a subtitle would be part of the gtable that gets made underneath the covers so it will “travel well” with the plot object itself. The function below makes a textGrob from whatever text we pass into it and does just that; it inserts the new grob into a new table row.
#' Add a subtitle to a ggplot object and draw plot on current graphics device. #' #' @param gg ggplot2 object #' @param label subtitle label #' @param fontfamily font family to use. The function doesn't pull any font #' information from \code{gg} so you should consider specifying fonts #' for the plot itself and here. Or send me code to make this smarter :-) #' @param fontsize font size #' @param hjust,vjust horizontal/vertical justification #' @param bottom_margin space between bottom of subtitle and plot (code{pts}) #' @param newpage draw new (empty) page first? #' @param vp viewport to draw plot in #' @param ... parameters passed to \code{gpar} in call to \code{textGrob} #' @return Invisibly returns the result of \code{\link{ggplot_build}}, which #' is a list with components that contain the plot itself, the data, #' information about the scales, panels etc. ggplot_with_subtitle <- function(gg, label="", fontfamily=NULL, fontsize=10, hjust=0, vjust=0, bottom_margin=5.5, newpage=is.null(vp), vp=NULL, ...) { if (is.null(fontfamily)) { gpr <- gpar(fontsize=fontsize, ...) } else { gpr <- gpar(fontfamily=fontfamily, fontsize=fontsize, ...) } subtitle <- textGrob(label, x=unit(hjust, "npc"), y=unit(hjust, "npc"), hjust=hjust, vjust=vjust, gp=gpr) data <- ggplot_build(gg) gt <- ggplot_gtable(data) gt <- gtable_add_rows(gt, grobHeight(subtitle), 2) gt <- gtable_add_grob(gt, subtitle, 3, 4, 3, 4, 8, "off", "subtitle") gt <- gtable_add_rows(gt, grid::unit(bottom_margin, "pt"), 3) if (newpage) grid.newpage() if (is.null(vp)) { grid.draw(gt) } else { if (is.character(vp)) seekViewport(vp) else pushViewport(vp) grid.draw(gt) upViewport() } invisible(data) }
The roxygen comments should give you an idea of how to work with it, and here it is in action:
subtitle <- "The percentage of Congressional members that are laywers has been\ncontinuously dropping since the 1960s" ggplot_with_subtitle(gg, subtitle, fontfamily="FranklinGothic-Book", bottom_margin=20, lineheight=0.9)

It deals with long annotations pretty well, too (I strwrapped the source text for the below at 100 characters). The text is senseless here, but it’s just for show (I had it handy…don’t judge…you’re getting free code :-):

I think this beats manually re-creating the wheel, even if you only infrequently use subtitles. It definitely beats hand-editing plots and is a bit more elegant and functional than using grid.arrange (et al) to mimic the functionality. It also beats futzing with panel margins and clipping to shoehorn a frankenmashup mess of geom_text or annotation_custom calls.
Kick the tyres, tell me where it breaks and if I can cover enough edge cases (or make it smarter) I’ll add it to my ggalt package.
Shiny Subtitle Gadget
Thanks to:
@hrbrmstr Sweet. Any thoughts of making it an RStudio addin?
— Andrew Clark (@pssGuy) March 13, 2016
you can now play with an experimental Shiny gadget which you can load by devtools::install_github("hrbrmstr/hrbrmisc") (that’s a temporary home for it, I use this pkg for testing/playing). Just select a ggplot2 object variable name in RStudio and then select “Add subtitle” from the Addins menu and give it a whirl. It looks like this:






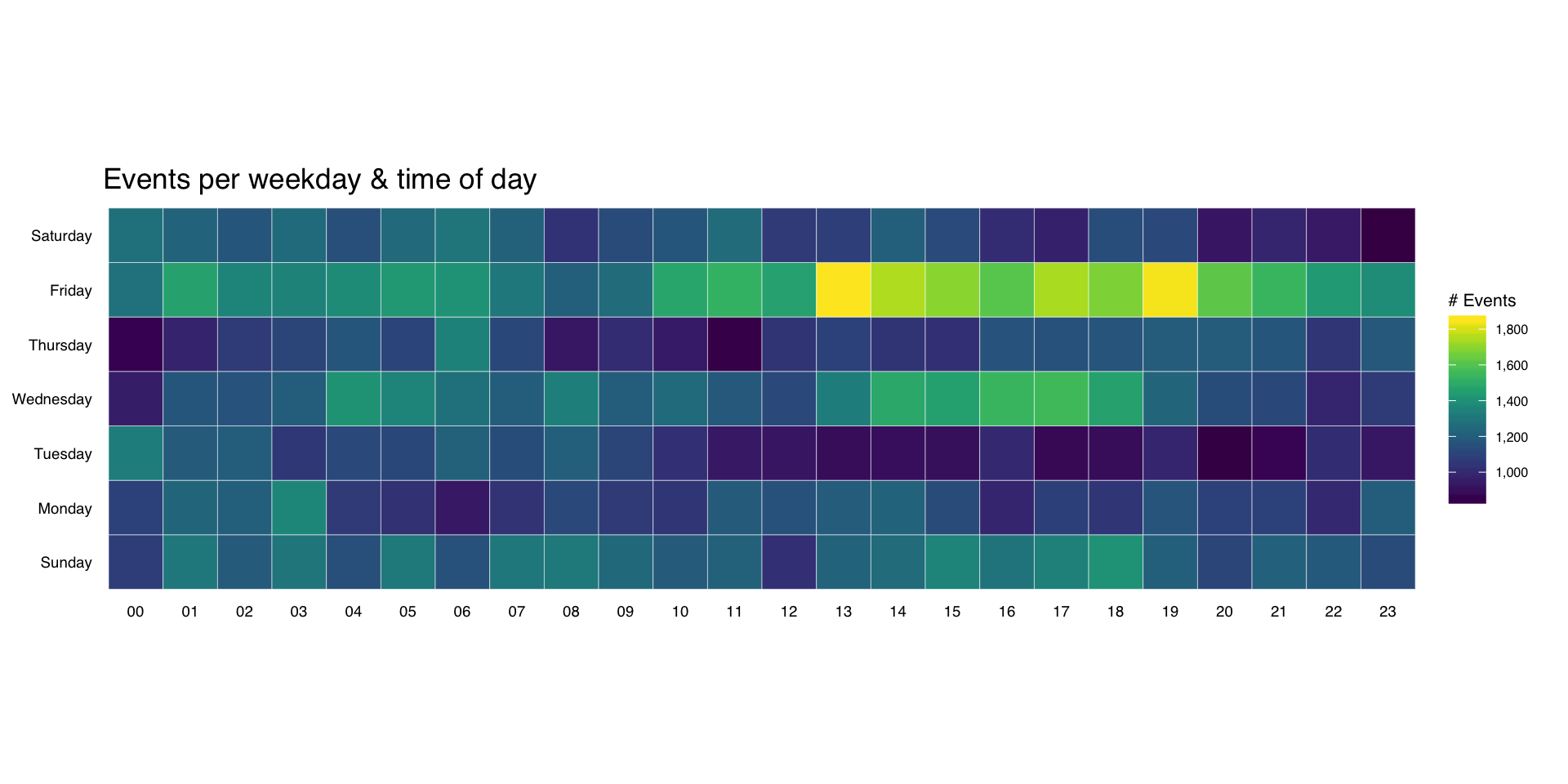
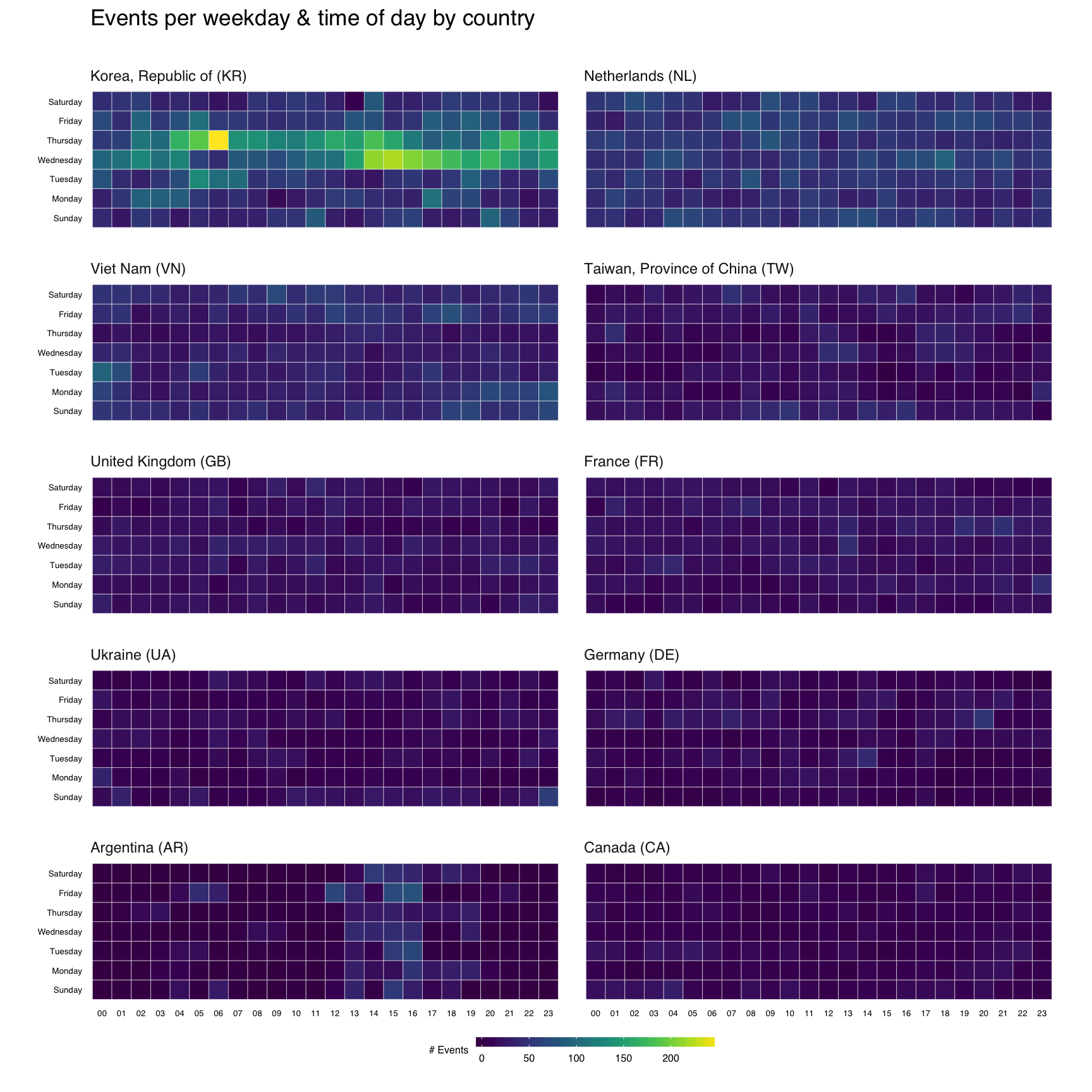
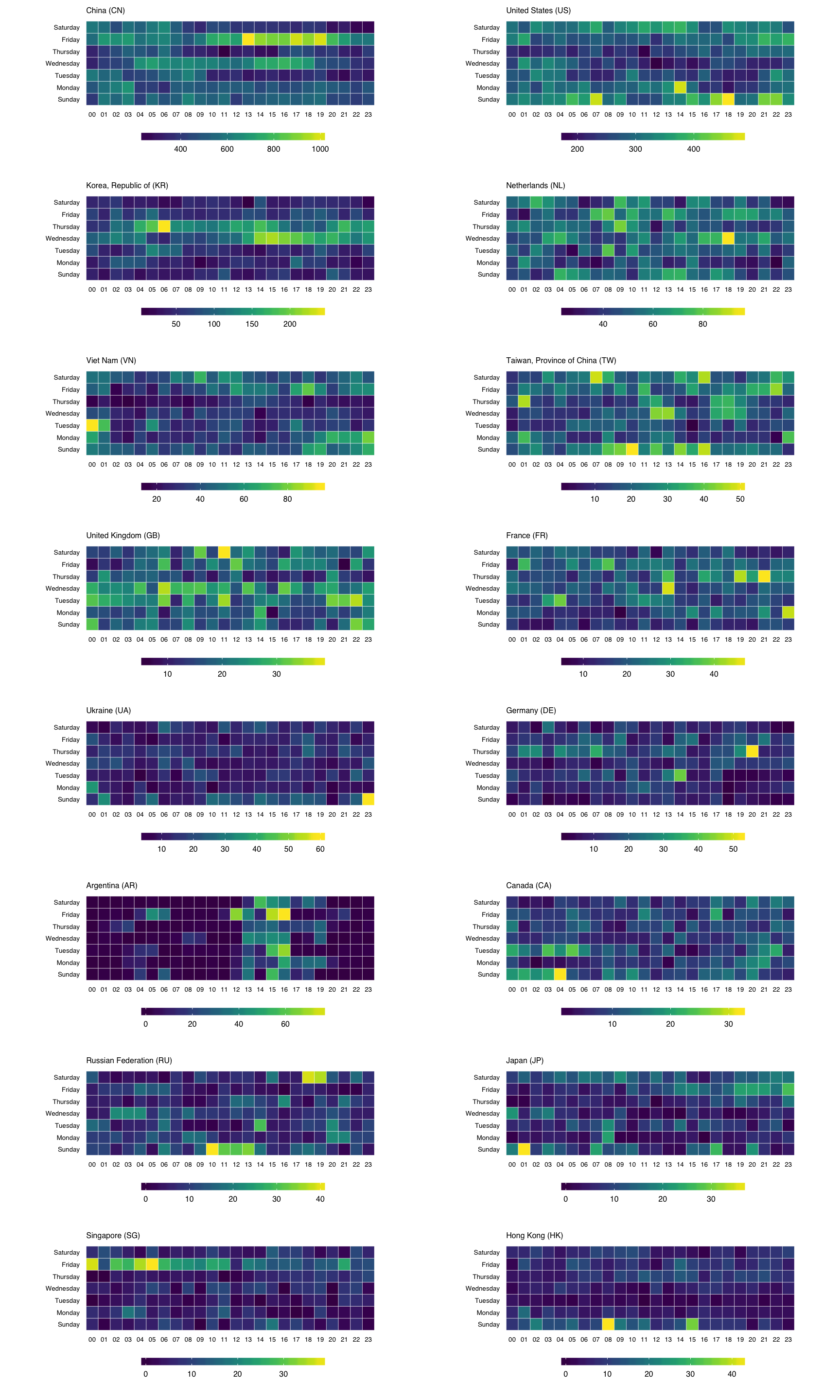
 By using an R package as the framework for the visualization, it’s possible to keep the data with the code and also organize and document the code in a way that makes it easy for folks to use and explore without cutting and pasting (our `source`ing) code. It also makes it possible to list all the dependencies for the project and help ensure they’ll be installed when someone tries to work with it.
By using an R package as the framework for the visualization, it’s possible to keep the data with the code and also organize and document the code in a way that makes it easy for folks to use and explore without cutting and pasting (our `source`ing) code. It also makes it possible to list all the dependencies for the project and help ensure they’ll be installed when someone tries to work with it.  The CSV file of places looks something like this:
The CSV file of places looks something like this: Because the project is in a pacakge, we can run package checks to see if we’re missing anything including other pacakge dependencies, function documentation and other details that the package tools are gleeful to point out. We can also include code to test out our various components to ensure they are behaving as expected (i.e. generating the right data/output).
Because the project is in a pacakge, we can run package checks to see if we’re missing anything including other pacakge dependencies, function documentation and other details that the package tools are gleeful to point out. We can also include code to test out our various components to ensure they are behaving as expected (i.e. generating the right data/output).
