Many R package authors (including myself) lump a collection of small, useful functions into some type of utils.R file and usually do not export the functions since they are (generally) designed to work on package internals rather than expose their functionality via the exported package API. Just like Batman’s utility belt, which can be customized for any mission, any set of utilities in a given R package will also likely be different from those in other packages.
I thought it would be neat to take a look at:
- just how many packages have one or more
util*.R files and what the most common file names are for them;
- utility function naming preferences — specifically snake-case, camel-case or dot-case
- what the most common “utility” functions names are across the packages
- coding style — specifically compare ratios of white space, full-line comments to code size
for all the published packages on CRAN.
There are many more questions one can ask and then use this corpus to answer, so we’ll close out the post with a link to it so any intrepid readers can do just that, especially since reproducing the first bit of this post would require a local CRAN mirror (which most folks — rightly so — do not have handy).
Acquiring and Transforming the Data We Need
 Since I have local CRAN mirror, it’s just a matter of iterating through all the package
Since I have local CRAN mirror, it’s just a matter of iterating through all the package tar.gz files in src/contrib and grepping through a tar listing of each for a pattern like "R/util.*$. That pattern isn’t perfect but it’s quick and we’ll be able to filter out any files it catches that don’t belong. I chose to use a small bash script for this but it’s possible to do this with R as well (an exercise left to the reader). The resultant data file looks a bit like the output from an ls -l (linux-ish) directory listing:
-rw-r--r-- 0 hornik users 1658 Jun 5 2016 AHR/R/util.R
-rw-r--r-- 0 ligges users 12609 Dec 13 2016 ALA4R/R/utilities_internal.R
-rw-r--r-- 0 hornik users 0 Feb 24 2017 AWR.Kinesis/R/utils.R
-rw-r--r-- 0 ligges users 4127 Aug 30 2017 AlphaVantageClient/R/utils.R
-rw-r--r-- 0 ligges users 121 Jan 19 2017 AmyloGram/R/utils.R
-rw-r--r-- 0 ligges users 2873 Jan 17 23:04 DT/R/utils.R
-rw-r--r-- 0 ligges users 3055 Jan 17 2017 cleanr/inst/source/R/utils.R
drwxr-xr-x 0 ligges users 0 Sep 24 2017 JGR/java/org/rosuda/JGR/util/
I made sure to show a few examples of where a better search pattern would have helped ensure lines like the three at the bottom of that listings aren’t included. But, we all often have to deal with imperfect data, so we’ll make sure to deal with that during the ingestion & cleanup process.
library(stringi)
library(hrbrthemes)
library(archive) # devtools::install_github("jimhester", "archive")
library(tidyverse)
# I ran readr::type_convert() once and it returns this column type spec. By using it
# for subsequent conversions, we'll gain reproducibility and data format change
# detection capabilities "for free"
cols(
permsissions = col_character(),
links = col_integer(),
owner = col_character(),
group = col_character(),
size = col_integer(),
month = col_character(),
day = col_integer(),
year_hr = col_character(),
path = col_character()
) -> tar_cols
# Now, we parse the tar verbose ('ls -l') listing
stri_read_lines("~/Data/pkutils.txt") %>% # stringi was loaded so might as well use it
stri_split_regex(" +", 9, simplify = TRUE) %>% # split input into 9 columns
as_data_frame() %>% # ^^ returns a matrix but data frames are more useful for our work
set_names(names(tar_cols$cols)) %>% # column names are useful and we can use our colspec for it
type_convert(col_types = tar_cols) %>% # see comment block before cols()
mutate(day = sprintf("%02d", day)) %>% # now we'll work on getting the date pieces to be a Date
mutate(year_hr = case_when( # the year_hr field can be either %Y or %H:%M depending on file 'recency'
stri_detect_fixed(year_hr, ":") &
(month %in% c("Jan", "Feb", "Mar", "Apr")) ~ "2018", # if %H:%M but 'starter' months it's 2018
stri_detect_fixed(year_hr, ":") &
(month %in% c("Dec", "Nov", "Oct", "Sep", "Aug", "Jul", "Jun")) ~ "2017", # %H:%M & 'end' months
TRUE ~ year_hr # already in %Y format
)) %>%
mutate(date= lubridate::mdy(sprintf("%s %s, %s", month, day, year_hr))) %>% # get a Date
mutate(pkg = stri_match_first_regex(path, "^(.*)/R/")[,2]) %>% # extract package name (stri_extract is also usable here)
mutate(fil = basename(path)) %>% # extrafct just the file name
filter(!is.na(pkg)) %>% # handle one type of wrongly included file
filter(!stri_detect_fixed(pkg, "/")) %>% # ande another
filter(!is.na(path)) -> xdf # and another; but we're done so we close with an assignment
glimpse(xdf)
## Observations: 1,746
## Variables: 12
## $ permsissions <chr> "-rw-r--r--", "-rw-r--r--", "-rw-r--r--", "-rw-r-...
## $ links <int> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0...
## $ owner <chr> "hornik", "ligges", "hornik", "ligges", "ligges",...
## $ group <chr> "users", "users", "users", "users", "users", "her...
## $ size <int> 1658, 12609, 0, 4127, 121, 52, 36977, 34198, 3676...
## $ month <chr> "Jun", "Dec", "Feb", "Aug", "Jan", "Aug", "Jan", ...
## $ day <chr> "05", "13", "24", "30", "19", "10", "06", "10", "...
## $ year_hr <chr> "2016", "2016", "2017", "2017", "2017", "2017", "...
## $ path <chr> "AHR/R/util.R", "ALA4R/R/utilities_internal.R", "...
## $ date <date> 2016-06-05, 2016-12-13, 2017-02-24, 2017-08-30, ...
## $ pkg <chr> "AHR", "ALA4R", "AWR.Kinesis", "AlphaVantageClien...
## $ fil <chr> "util.R", "utilities_internal.R", "utils.R", "uti...
To the analysis!
Finding the Utility of ‘util’s
A careful look at the glimpse() listing shows we have 1,745 files that begin with util, but how many packages have at least one util files?
nrow(distinct(xdf, pkg))
## [1] 1397
That’s roughly 10% of CRAN, but doesn’t mean other packages do not have “utility belt” functions since other authors may have just been more creative or deliberate with their file naming conventions.
Readers with keen eyes may have noticed we spent some deliberate CPU cycles to get a Date column. Part of that was to show how to do that (mostly as an example for folks new to R) but we also did it to ask temporal questions, such as “Are package ‘utility belts’ a “new” thing?”. The data suggests that utility belts are products/attributes of more recently published or updated packages:
distinct(xdf, pkg, date) %>%
mutate(yr = as.integer(lubridate::year(date))) %>%
count(yr) %>%
complete(yr, fill=list(n=0)) %>%
ggplot(aes(yr, n)) +
geom_col(fill="lightslategray", width=0.65) +
labs(
x = NULL, y = "Package count",
title = "Recently published or updated packages tend to have more 'util'\nthan older/less actively-maintained ones",
subtitle = "Count of packages (by year) with 'util's"
) +
theme_ipsum_rc(grid="Y")

We could answer this more completely by going through the CRAN archives for all these packages, but for now we’ll just see which packages might have helped set this trend going:
distinct(xdf, pkg, date) %>%
arrange(date) %>%
print(n=20)
## # A tibble: 1,540 x 2
## date pkg
## 1 1980-01-01 bsts
## 2 2006-06-28 evdbayes
## 3 2006-11-29 hexView
## 4 2006-12-17 StatDataML
## 5 2007-10-05 tpr
## 6 2007-11-07 seqinr
## 7 2007-11-26 registry
## 8 2008-07-25 ramps
## 9 2008-10-23 RobAStBase
## 10 2009-02-23 vcd
## 11 2009-06-26 ttutils
## 12 2009-07-03 histogram
## 13 2009-11-27 polynom
## 14 2009-11-27 tau
## 15 2010-01-05 itertools
## 16 2010-01-22 tableplot
## 17 2010-06-09 rbugs
## 18 2011-03-17 playwith
## 19 2011-05-11 marelac
## 20 2011-10-11 timeSeries
## # ... with 1,520 more rows
Going back to our corpus, what are the most common names for these utility belt files?
## count(xdf, fil, sort=TRUE) %>%
## mutate(pct = scales::percent(n/sum(n))) %>%
## print(n=20)
## # A tibble: 409 x 3
## fil n pct
## 1 utils.R 865 49.5%
## 2 utilities.R 145 8.3%
## 3 util.R 134 7.7%
## 4 utils.r 68 3.9%
## 5 utility.R 47 2.7%
## 6 utility_functions.R 25 1.4%
## 7 util.r 16 0.9%
## 8 utilities.r 14 0.8%
## 9 utils-pipe.R 9 0.5%
## 10 utilityFunctions.R 6 0.3%
## 11 utils-format.r 3 0.2%
## 12 util_functions.R 2 0.1%
## 13 util_rescale.R 2 0.1%
## 14 util-aux.R 2 0.1%
## 15 util-checkparam.R 2 0.1%
## 16 util-startarg.R 2 0.1%
## 17 utilcmst.R 2 0.1%
## 18 utilhot.R 2 0.1%
## 19 utilities_internal.R 2 0.1%
## 20 utility-functions.R 2 0.1%
## # ... with 389 more rows
Over 50% of other CRAN packages are as “un-creative” as I am when it comes to naming these files.
Let’s see how packed these belts are:
ggplot(xdf, aes(x="", size)) +
ggbeeswarm::geom_quasirandom(
fill="lightslategray", color="white",
alpha=1/2, stroke=0.25, size=3, shape=21
) +
geom_boxplot(fill="#00000000", outlier.colour = "#00000000") +
geom_text(
data=data_frame(), aes(x=-Inf, y=median(xdf$size), label="Median:\n2,717"),
hjust = 0, family = font_rc, size = 3, color = "lightslateblue"
) +
scale_y_comma(
name = "File size", trans="log10", limits=c(NA, 200000),
breaks = c(10, 100, 1000, 10000, 100000)
) +
labs(
x = NULL,
title = "Most 'util' files are between 1K and 10K in size",
caption = "Note y-axis log10 scale"
) +
theme_ipsum_rc(grid="Y")

We’ll need to do a bit more data collection to answer the last two questions.
Focus on Functions
 To examine function names and source code statistics, we’ll need to read in the contents of each file and parse them. Let’s do that first bit with some help from the
To examine function names and source code statistics, we’ll need to read in the contents of each file and parse them. Let’s do that first bit with some help from the archive package which will help us open up these compressed tar files and pull out the file(s) we need from them vs have to code this up more manually.
Again, this code is only reproducible if you have CRAN handy, but soon (promise!) you’ll have a file you can work with for the remainder of the post:
extract_source <- function(pkg, fil, .pb = NULL) {
if (!is.null(.pb)) .pb$tick()$print()
list.files(
path = "/cran/src/contrib", # my path to local CRAN
pattern = sprintf("^%s_.*gz", pkg), # rough pattern for the package archive filename
recursive = FALSE,
full.names = TRUE
) -> tgt
con <- archive_read(tgt[1], fil)
src <- readLines(con, warn = FALSE)
close(con)
paste0(src, collapse="\n")
}
pb <- progress_estimated(nrow(xdf))
xdf <- mutate(xdf, file_src = map2_chr(pkg, path, extract_source, .pb=pb))
That (on-drive) ~10MB data frame is in https://rud.is/dl/utility-belt.rds. The rest of the post builds off of it so you can start coding along at home now.
Let’s extract the function names:
# we'll use these two functions to help test whether bits
# of our parsed code are, indeed, functions.
#
# Alternately: "I heard you liked functions so I made
# functions to help you find functions"
#
# we could have used `rlang` helpers here, but I had these
# handy from pre-`rlang` days.
is_assign <- function(x) {
as.character(x) %in% c('<-', '=', '<<-', 'assign')
}
is_func <- function(x) {
is.call(x) &&
is_assign(x[[1]]) &&
is.call(x[[3]]) &&
(x[[3]][[1]] == quote(`function`))
}
read_rds("~/Data/utility-belt.rds") %>% # I have this file in ~/Data; change this for your location
mutate(parsed = map(file_src, ~parse(text = .x, keep.source = TRUE))) %>% # parse each file
mutate(func_names = map(parsed, ~{ # go through parsed file
keep(.x, is_func) %>% # and only keep functions
map(~as.character(.x[[2]])) %>% # extract the function name
flatten_chr() # return a character vector
})) -> xdf
With those handy, we can see if there are any commonalities across all these packages:
select(xdf, pkg, fil, func_names) %>%
unnest() %>%
count(func_names, sort=TRUE) %>%
print(n=20)
## func_names n
## 1 %||% 84
## 2 compact 19
## 3 isFALSE 19
## 4 assertthat::on_failure 16
## 5 is_windows 16
## 6 trim 14
## 7 .on Load 13 # (IRL there's no space here but the WP input sanitizer hates this word due to js abuse
## 8 names2 12
## 9 dots 11
## 10 is_string 11
## 11 vlapply 11
## 12 .onAttach 10
## 13 error.bars 10
## 14 normalize 10
## 15 vcapply 10
## 16 cat0 9
## 17 collapse 9
## 18 err 9
## 19 getmin 9
## 20 is_dir 9
## # ... with 1.252e+04 more rows
We can also see if there are common case conventions:
select(xdf, pkg, fil, func_names) %>%
unnest() %>%
mutate(is_camel = (!stri_detect_fixed(func_names, "_")) &
(!stri_detect_regex(func_names, "[[:alpha:]]\\.[[:alpha:]]")) &
(stri_detect_regex(func_names, "[A-Z]"))) %>%
mutate(is_dotcase = stri_detect_regex(func_names, "[[:alpha:]]\\.[[:alpha:]]")) %>%
mutate(is_snake = stri_detect_fixed(func_names, "_") &
(!stri_detect_regex(func_names, "[[:alpha:]]\\.[[:alpha:]]"))) -> case_hunt
count(case_hunt, is_camel, is_dotcase, is_snake) %>%
mutate(pct = scales::percent(n/sum(n))) %>%
mutate(description = c(
"one-'word' names",
"snake_case",
"dot.case",
"camelCase"
)) %>%
arrange(n) %>%
mutate(description = factor(description, description)) %>%
ggplot(aes(description, n)) +
geom_col(fill="lightslategray", width=0.65) +
geom_label(aes(y = n, label=pct), label.size=0, family=font_rc, nudge_y=150) +
scale_y_comma("Number of functions") +
labs(
x=NULL,
title = "dot.case does not seem to be en-vogue for utility belt functions"
) +
theme_ipsum_rc(grid="Y")

I had a hunch that isX…()/is_x…() could be likely names for utility belt functions, so let’s normalize the function names to snake_case and see if that’s true:
select(xdf, pkg, fil, func_names) %>%
unnest() %>%
filter(stri_detect_regex(func_names, "^(\\.is|is)")) %>%
mutate(func_names = snakecase::to_snake_case(func_names)) %>%
count(func_names, sort=TRUE)
## # A tibble: 547 x 2
## func_names n
## 1 is_false 24
## 2 is_windows 19
## 3 is_string 18
## 4 is_empty 13
## 5 is_dir 11
## 6 is_formula 11
## 7 is_installed 11
## 8 is_linux 9
## 9 is_na 9
## 10 is_error 8
## # ... with 537 more rows
Only 5% (819) out of 14,123 extracted function names are is_; not overwhelming, but a respectable slice.
There are more questions we could ask of function names and styles, but we’ll leave some work for y’all to do on your own.
Let’s head over to the final rooftop exercise.
Code, Comment & Blank Line Density
 Since we have the raw source, we can also take a look at coding style. There are many questions we could ask here and more than a few packages we could draw on to help answer them. For now, we’ll just take a look at the mean ratios of comments and blank lines to code across the packages in this utility belt corpus and give you the opportunity to tease out other interesting tidbits such as “what base R and other package functions are most often used in utility belt functions?” or “are package authors using evil
Since we have the raw source, we can also take a look at coding style. There are many questions we could ask here and more than a few packages we could draw on to help answer them. For now, we’ll just take a look at the mean ratios of comments and blank lines to code across the packages in this utility belt corpus and give you the opportunity to tease out other interesting tidbits such as “what base R and other package functions are most often used in utility belt functions?” or “are package authors using evil = for assignment or proper <-?”.
xdf %>%
mutate(
num_lines = stri_count_fixed(xdf$file_src, "\n"),
num_blank_lines = stri_count_regex(xdf$file_src, "^[[:space:]]*$", opts_regex = stri_opts_regex(multiline=TRUE)),
num_whole_line_comments = lengths(cmnt_df$comments),
comment_density = num_whole_line_comments / (num_lines - num_blank_lines - num_whole_line_comments),
blank_density = num_blank_lines / (num_lines - num_whole_line_comments)
) %>%
select(-permsissions, -links, -owner, -group, month, -day, -year_hr) -> xdf
# now compute mean ratios
group_by(xdf, pkg) %>%
summarise(
`Comment-to-code Ratio` = mean(comment_density),
`Blank lines-to-code Ratio` = mean(blank_density)
) %>%
ungroup() %>%
filter(!is.infinite(`Comment-to-code Ratio`)) %>%
filter(!is.nan(`Comment-to-code Ratio`)) %>%
filter(!is.infinite(`Blank lines-to-code Ratio`)) %>%
filter(!is.nan(`Blank lines-to-code Ratio`)) %>%
gather(measure, value, -pkg) -> code_ratios
# we want to label the median values
group_by(code_ratios, measure) %>%
summarise(median = median(value)) -> code_ratio_meds
ggplot(code_ratios, aes(measure, value, group=measure)) +
ggbeeswarm::geom_quasirandom(
fill="lightslategray", color="#2b2b2b", alpha=1/2,
stroke=0.25, size=3, shape=21
) +
geom_boxplot(fill="#00000000", outlier.colour = "#00000000") +
geom_label(
data = code_ratio_meds,
aes(-Inf, c(0.3, 5), label=sprintf("Median:\n%s", round(median, 2)), group=measure),
family = font_rc, size=3, color="lightslateblue", hjust = 0, label.size=0
) +
scale_y_continuous() +
labs(
x = NULL, y = NULL,
caption = "Note free y scale"
) +
facet_wrap(~measure, scales="free") +
theme_ipsum_rc(grid="Y", strip_text_face = "bold") +
theme(axis.text.x=element_blank())

FIN
You can find the (on-drive) ~10MB data frame is at: https://rud.is/dl/utility-belt.rds.
All the above code in this gist: https://gist.github.com/hrbrmstr/33d29bb39eaa7f2f1e95308038f85b59.
If you do your own ‘utility belt’ analyses, drop a note in the comments with a link to your findings!






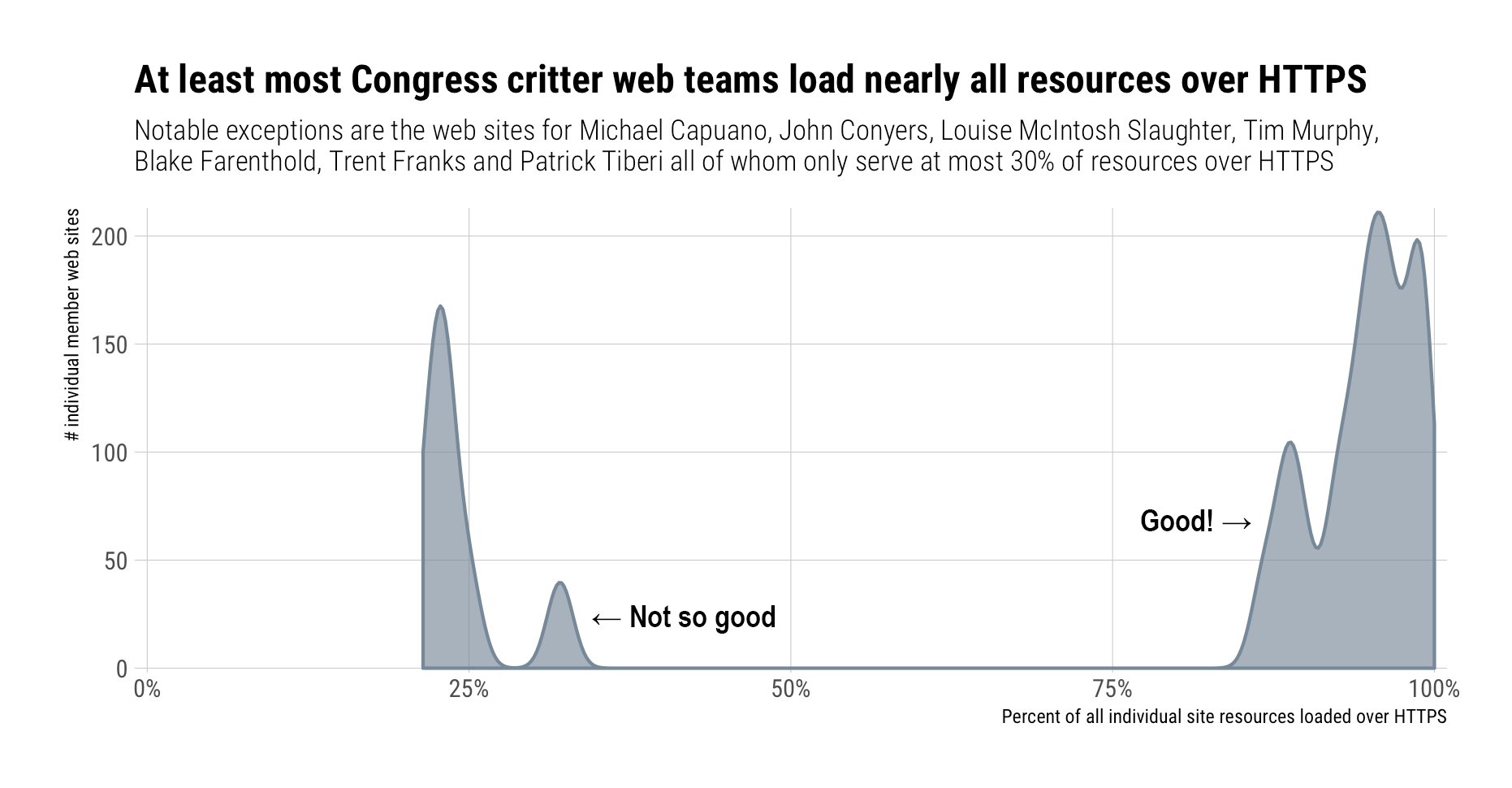



A Word About Tracking On This Site
Since I just railed against Congress for being a bit two-faced about privacy I thought some
rud.issite disclosure would be in order.At present, third-party tracking is limited to:
fonts.googleapis.com. There are a few more other DNS pre-fetches that I’m also going to try to eradicate (but that aren’t showing up in my uBlock Origin likely to to/etc/hostsblocks);The above came from an in-browser uBlock Origin report.
I ran a
splashr::render_har()— which is how I measured things for the Congressional privacy post — on one of my pages and this is the result:Props on WordPress capturing
w.org! I’m still ticked Microsoft stolebob.comfrom me ages ago.As you can see, most resources load from my site and none come from Twitter, Facebook or Google Plus.
I run WordPress for a ton of reasons too long to go into for this post, so I’m likely not going to change anything about that list (apart from the DNS pre-fetching).
Hopefully that will abate any concerns visitors might have, especially after reading the post about Congress.