I was about to embark on setting up a background task to sift through R package PDFs for traces of functions that “omit NA values” as a surprise present for Colin Fay and Sir Tierney:
When I got distracted by a PDF in the CRAN doc/contrib directory: Short-refcard.pdf. I’m not a big reference card user but students really like them and after seeing what it was I remembered having seen the document ages ago, but never associated it with CRAN before.
I saw:
by Tom Short, EPRI PEAC, tshort@epri-peac.com 2004-11-07 Granted to the public domain. See www. Rpad. org for the source and latest version. Includes material from R for Beginners by Emmanuel Paradis (with permission).
at the top of the card. The link (which I’ve made unclickable for reasons you’ll see in a sec — don’t visit that URL) was clickable and I tapped it as I wanted to see if it had changed since 2004.

You can open that image in a new tab to see the full, rendered site and take a moment to see if you can find the section that links to objectionable — and, potentially malicious — content. It’s easy to spot.
I made a likely correct assumption that Tom Short had nothing to do with this and wanted to dig into it a bit further to see when this may have happened. So, don your bestest deerstalker and follow along as we see when this may have happened.
Digging In Domain Land
We’ll need some helpers to poke around this data in a safe manner:
library(wayback) # devtools::install_github("hrbrmstr/wayback")
library(ggTimeSeries) # devtools::install_github("AtherEnergy/ggTimeSeries")
library(splashr) # devtools::install_github("hrbrmstr/splashr")
library(passivetotal) # devtools::install_github("hrbrmstr/passivetotal")
library(cymruservices)
library(magick)
library(tidyverse)
(You’ll need to get a RiskIQ PassiveTotal key to use those functions. Also, please donate to Archive.org if you use the wayback package.)
Now, let’s see if the main Rpad content URL is in the wayback machine:
glimpse(archive_available("http://www.rpad.org/Rpad/"))
## Observations: 1
## Variables: 5
## $ url <chr> "http://www.rpad.org/Rpad/"
## $ available <lgl> TRUE
## $ closet_url <chr> "http://web.archive.org/web/20170813053454/http://ww...
## $ timestamp <dttm> 2017-08-13
## $ status <chr> "200"
It is! Let’s see how many versions of it are in the archive:
x <- cdx_basic_query("http://www.rpad.org/Rpad/")
ts_range <- range(x$timestamp)
count(x, timestamp) %>%
ggplot(aes(timestamp, n)) +
geom_segment(aes(xend=timestamp, yend=0)) +
labs(x=NULL, y="# changes in year", title="rpad.org Wayback Change Timeline") +
theme_ipsum_rc(grid="Y")

count(x, timestamp) %>%
mutate(Year = lubridate::year(timestamp)) %>%
complete(timestamp=seq(ts_range[1], ts_range[2], "1 day")) %>%
filter(!is.na(timestamp), !is.na(Year)) %>%
ggplot(aes(date = timestamp, fill = n)) +
stat_calendar_heatmap() +
viridis::scale_fill_viridis(na.value="white", option = "magma") +
facet_wrap(~Year, ncol=1) +
labs(x=NULL, y=NULL, title="rpad.org Wayback Change Timeline") +
theme_ipsum_rc(grid="") +
theme(axis.text=element_blank()) +
theme(panel.spacing = grid::unit(0.5, "lines"))

There’s a big span between 2008/9 and 2016/17. Let’s poke around there a bit. First 2016:
tm <- get_timemap("http://www.rpad.org/Rpad/")
(rurl <- filter(tm, lubridate::year(anytime::anydate(datetime)) == 2016))
## # A tibble: 1 x 5
## rel link type
## <chr> <chr> <chr>
## 1 memento http://web.archive.org/web/20160629104907/http://www.rpad.org:80/Rpad/ <NA>
## # ... with 2 more variables: from <chr>, datetime <chr>
(p2016 <- render_png(url = rurl$link))

Hrm. Could be server or network errors.
Let’s go back to 2009.
(rurl <- filter(tm, lubridate::year(anytime::anydate(datetime)) == 2009))
## # A tibble: 4 x 5
## rel link type
## <chr> <chr> <chr>
## 1 memento http://web.archive.org/web/20090219192601/http://rpad.org:80/Rpad <NA>
## 2 memento http://web.archive.org/web/20090322163146/http://www.rpad.org:80/Rpad <NA>
## 3 memento http://web.archive.org/web/20090422082321/http://www.rpad.org:80/Rpad <NA>
## 4 memento http://web.archive.org/web/20090524155658/http://www.rpad.org:80/Rpad <NA>
## # ... with 2 more variables: from <chr>, datetime <chr>
(p2009 <- render_png(url = rurl$link[4]))

If you poke around that, it looks like the original Rpad content, so it was “safe” back then.
(rurl <- filter(tm, lubridate::year(anytime::anydate(datetime)) == 2017))
## # A tibble: 6 x 5
## rel link type
## <chr> <chr> <chr>
## 1 memento http://web.archive.org/web/20170323222705/http://www.rpad.org/Rpad <NA>
## 2 memento http://web.archive.org/web/20170331042213/http://www.rpad.org/Rpad/ <NA>
## 3 memento http://web.archive.org/web/20170412070515/http://www.rpad.org/Rpad/ <NA>
## 4 memento http://web.archive.org/web/20170518023345/http://www.rpad.org/Rpad/ <NA>
## 5 memento http://web.archive.org/web/20170702130918/http://www.rpad.org/Rpad/ <NA>
## 6 memento http://web.archive.org/web/20170813053454/http://www.rpad.org/Rpad/ <NA>
## # ... with 2 more variables: from <chr>, datetime <chr>
(p2017 <- render_png(url = rurl$link[1]))
I won’t break your browser and add another giant image, but that one has the icky content. So, it’s a relatively recent takeover and it’s likely that whomever added the icky content links did so to try to ensure those domains and URLs have both good SEO and a positive reputation.
Let’s see if they were dumb enough to make their info public:
rwho <- passive_whois("rpad.org")
str(rwho, 1)
## List of 18
## $ registryUpdatedAt: chr "2016-10-05"
## $ admin :List of 10
## $ domain : chr "rpad.org"
## $ registrant :List of 10
## $ telephone : chr "5078365503"
## $ organization : chr "WhoisGuard, Inc."
## $ billing : Named list()
## $ lastLoadedAt : chr "2017-03-14"
## $ nameServers : chr [1:2] "ns-1147.awsdns-15.org" "ns-781.awsdns-33.net"
## $ whoisServer : chr "whois.publicinterestregistry.net"
## $ registered : chr "2004-06-15"
## $ contactEmail : chr "411233718f2a4cad96274be88d39e804.protect@whoisguard.com"
## $ name : chr "WhoisGuard Protected"
## $ expiresAt : chr "2018-06-15"
## $ registrar : chr "eNom, Inc."
## $ compact :List of 10
## $ zone : Named list()
## $ tech :List of 10
Nope. #sigh
Is this site considered “malicious”?
(rclass <- passive_classification("rpad.org"))
## $everCompromised
## NULL
Nope. #sigh
What’s the hosting history for the site?
rdns <- passive_dns("rpad.org")
rorig <- bulk_origin(rdns$results$resolve)
tbl_df(rdns$results) %>%
type_convert() %>%
select(firstSeen, resolve) %>%
left_join(select(rorig, resolve=ip, as_name=as_name)) %>%
arrange(firstSeen) %>%
print(n=100)
## # A tibble: 88 x 3
## firstSeen resolve as_name
## <dttm> <chr> <chr>
## 1 2009-12-18 11:15:20 144.58.240.79 EPRI-PA - Electric Power Research Institute, US
## 2 2016-06-19 00:00:00 208.91.197.132 CONFLUENCE-NETWORK-INC - Confluence Networks Inc, VG
## 3 2016-07-29 00:00:00 208.91.197.27 CONFLUENCE-NETWORK-INC - Confluence Networks Inc, VG
## 4 2016-08-12 20:46:15 54.230.14.253 AMAZON-02 - Amazon.com, Inc., US
## 5 2016-08-16 14:21:17 54.230.94.206 AMAZON-02 - Amazon.com, Inc., US
## 6 2016-08-19 20:57:04 54.230.95.249 AMAZON-02 - Amazon.com, Inc., US
## 7 2016-08-26 20:54:02 54.192.197.200 AMAZON-02 - Amazon.com, Inc., US
## 8 2016-09-12 10:35:41 52.84.40.164 AMAZON-02 - Amazon.com, Inc., US
## 9 2016-09-17 07:43:03 54.230.11.212 AMAZON-02 - Amazon.com, Inc., US
## 10 2016-09-23 18:17:50 54.230.202.223 AMAZON-02 - Amazon.com, Inc., US
## 11 2016-09-30 19:47:31 52.222.174.253 AMAZON-02 - Amazon.com, Inc., US
## 12 2016-10-24 17:44:38 52.85.112.250 AMAZON-02 - Amazon.com, Inc., US
## 13 2016-10-28 18:14:16 52.222.174.231 AMAZON-02 - Amazon.com, Inc., US
## 14 2016-11-11 10:44:22 54.240.162.201 AMAZON-02 - Amazon.com, Inc., US
## 15 2016-11-17 04:34:15 54.192.197.242 AMAZON-02 - Amazon.com, Inc., US
## 16 2016-12-16 17:49:29 52.84.32.234 AMAZON-02 - Amazon.com, Inc., US
## 17 2016-12-19 02:34:32 54.230.141.240 AMAZON-02 - Amazon.com, Inc., US
## 18 2016-12-23 14:25:32 54.192.37.182 AMAZON-02 - Amazon.com, Inc., US
## 19 2017-01-20 17:26:28 52.84.126.252 AMAZON-02 - Amazon.com, Inc., US
## 20 2017-02-03 15:28:24 52.85.94.225 AMAZON-02 - Amazon.com, Inc., US
## 21 2017-02-10 19:06:07 52.85.94.252 AMAZON-02 - Amazon.com, Inc., US
## 22 2017-02-17 21:37:21 52.85.63.229 AMAZON-02 - Amazon.com, Inc., US
## 23 2017-02-24 21:43:45 52.85.63.225 AMAZON-02 - Amazon.com, Inc., US
## 24 2017-03-05 12:06:32 54.192.19.242 AMAZON-02 - Amazon.com, Inc., US
## 25 2017-04-01 00:41:07 54.192.203.223 AMAZON-02 - Amazon.com, Inc., US
## 26 2017-05-19 00:00:00 13.32.246.44 AMAZON-02 - Amazon.com, Inc., US
## 27 2017-05-28 00:00:00 52.84.74.38 AMAZON-02 - Amazon.com, Inc., US
## 28 2017-06-07 08:10:32 54.230.15.154 AMAZON-02 - Amazon.com, Inc., US
## 29 2017-06-07 08:10:32 54.230.15.142 AMAZON-02 - Amazon.com, Inc., US
## 30 2017-06-07 08:10:32 54.230.15.168 AMAZON-02 - Amazon.com, Inc., US
## 31 2017-06-07 08:10:32 54.230.15.57 AMAZON-02 - Amazon.com, Inc., US
## 32 2017-06-07 08:10:32 54.230.15.36 AMAZON-02 - Amazon.com, Inc., US
## 33 2017-06-07 08:10:32 54.230.15.129 AMAZON-02 - Amazon.com, Inc., US
## 34 2017-06-07 08:10:32 54.230.15.61 AMAZON-02 - Amazon.com, Inc., US
## 35 2017-06-07 08:10:32 54.230.15.51 AMAZON-02 - Amazon.com, Inc., US
## 36 2017-07-16 09:51:12 54.230.187.155 AMAZON-02 - Amazon.com, Inc., US
## 37 2017-07-16 09:51:12 54.230.187.184 AMAZON-02 - Amazon.com, Inc., US
## 38 2017-07-16 09:51:12 54.230.187.125 AMAZON-02 - Amazon.com, Inc., US
## 39 2017-07-16 09:51:12 54.230.187.91 AMAZON-02 - Amazon.com, Inc., US
## 40 2017-07-16 09:51:12 54.230.187.74 AMAZON-02 - Amazon.com, Inc., US
## 41 2017-07-16 09:51:12 54.230.187.36 AMAZON-02 - Amazon.com, Inc., US
## 42 2017-07-16 09:51:12 54.230.187.197 AMAZON-02 - Amazon.com, Inc., US
## 43 2017-07-16 09:51:12 54.230.187.185 AMAZON-02 - Amazon.com, Inc., US
## 44 2017-07-17 13:10:13 54.239.168.225 AMAZON-02 - Amazon.com, Inc., US
## 45 2017-08-06 01:14:07 52.222.149.75 AMAZON-02 - Amazon.com, Inc., US
## 46 2017-08-06 01:14:07 52.222.149.172 AMAZON-02 - Amazon.com, Inc., US
## 47 2017-08-06 01:14:07 52.222.149.245 AMAZON-02 - Amazon.com, Inc., US
## 48 2017-08-06 01:14:07 52.222.149.41 AMAZON-02 - Amazon.com, Inc., US
## 49 2017-08-06 01:14:07 52.222.149.38 AMAZON-02 - Amazon.com, Inc., US
## 50 2017-08-06 01:14:07 52.222.149.141 AMAZON-02 - Amazon.com, Inc., US
## 51 2017-08-06 01:14:07 52.222.149.163 AMAZON-02 - Amazon.com, Inc., US
## 52 2017-08-06 01:14:07 52.222.149.26 AMAZON-02 - Amazon.com, Inc., US
## 53 2017-08-11 19:11:08 216.137.61.247 AMAZON-02 - Amazon.com, Inc., US
## 54 2017-08-21 20:44:52 13.32.253.116 AMAZON-02 - Amazon.com, Inc., US
## 55 2017-08-21 20:44:52 13.32.253.247 AMAZON-02 - Amazon.com, Inc., US
## 56 2017-08-21 20:44:52 13.32.253.117 AMAZON-02 - Amazon.com, Inc., US
## 57 2017-08-21 20:44:52 13.32.253.112 AMAZON-02 - Amazon.com, Inc., US
## 58 2017-08-21 20:44:52 13.32.253.42 AMAZON-02 - Amazon.com, Inc., US
## 59 2017-08-21 20:44:52 13.32.253.162 AMAZON-02 - Amazon.com, Inc., US
## 60 2017-08-21 20:44:52 13.32.253.233 AMAZON-02 - Amazon.com, Inc., US
## 61 2017-08-21 20:44:52 13.32.253.29 AMAZON-02 - Amazon.com, Inc., US
## 62 2017-08-23 14:24:15 216.137.61.164 AMAZON-02 - Amazon.com, Inc., US
## 63 2017-08-23 14:24:15 216.137.61.146 AMAZON-02 - Amazon.com, Inc., US
## 64 2017-08-23 14:24:15 216.137.61.21 AMAZON-02 - Amazon.com, Inc., US
## 65 2017-08-23 14:24:15 216.137.61.154 AMAZON-02 - Amazon.com, Inc., US
## 66 2017-08-23 14:24:15 216.137.61.250 AMAZON-02 - Amazon.com, Inc., US
## 67 2017-08-23 14:24:15 216.137.61.217 AMAZON-02 - Amazon.com, Inc., US
## 68 2017-08-23 14:24:15 216.137.61.54 AMAZON-02 - Amazon.com, Inc., US
## 69 2017-08-25 19:21:58 13.32.218.245 AMAZON-02 - Amazon.com, Inc., US
## 70 2017-08-26 09:41:34 52.85.173.67 AMAZON-02 - Amazon.com, Inc., US
## 71 2017-08-26 09:41:34 52.85.173.186 AMAZON-02 - Amazon.com, Inc., US
## 72 2017-08-26 09:41:34 52.85.173.131 AMAZON-02 - Amazon.com, Inc., US
## 73 2017-08-26 09:41:34 52.85.173.18 AMAZON-02 - Amazon.com, Inc., US
## 74 2017-08-26 09:41:34 52.85.173.91 AMAZON-02 - Amazon.com, Inc., US
## 75 2017-08-26 09:41:34 52.85.173.174 AMAZON-02 - Amazon.com, Inc., US
## 76 2017-08-26 09:41:34 52.85.173.210 AMAZON-02 - Amazon.com, Inc., US
## 77 2017-08-26 09:41:34 52.85.173.88 AMAZON-02 - Amazon.com, Inc., US
## 78 2017-08-27 22:02:41 13.32.253.169 AMAZON-02 - Amazon.com, Inc., US
## 79 2017-08-27 22:02:41 13.32.253.203 AMAZON-02 - Amazon.com, Inc., US
## 80 2017-08-27 22:02:41 13.32.253.209 AMAZON-02 - Amazon.com, Inc., US
## 81 2017-08-29 13:17:37 54.230.141.201 AMAZON-02 - Amazon.com, Inc., US
## 82 2017-08-29 13:17:37 54.230.141.83 AMAZON-02 - Amazon.com, Inc., US
## 83 2017-08-29 13:17:37 54.230.141.30 AMAZON-02 - Amazon.com, Inc., US
## 84 2017-08-29 13:17:37 54.230.141.193 AMAZON-02 - Amazon.com, Inc., US
## 85 2017-08-29 13:17:37 54.230.141.152 AMAZON-02 - Amazon.com, Inc., US
## 86 2017-08-29 13:17:37 54.230.141.161 AMAZON-02 - Amazon.com, Inc., US
## 87 2017-08-29 13:17:37 54.230.141.38 AMAZON-02 - Amazon.com, Inc., US
## 88 2017-08-29 13:17:37 54.230.141.151 AMAZON-02 - Amazon.com, Inc., US
Unfortunately, I expected this. The owner keeps moving it around on AWS infrastructure.
So What?
This was an innocent link in a document on CRAN that went to a site that looked legit. A clever individual or organization found the dead domain and saw an opportunity to legitimize some fairly nasty stuff.
Now, I realize nobody is likely using “Rpad” anymore, but this type of situation can happen to any registered domain. If this individual or organization were doing more than trying to make objectionable content legit, they likely could have succeeded, especially if they enticed you with a shiny new devtools::install_…() link with promises of statistically sound animated cat emoji gif creation tools. They did an eerily good job of making this particular site still seem legit.
There’s nothing most folks can do to “fix” that site or have it removed. I’m not sure CRAN should remove the helpful PDF, but with a clickable link, it might be a good thing to suggest.
You’ll see that I used the splashr package (which has been submitted to CRAN but not there yet). It’s a good way to work with potentially malicious web content since you can “see” it and mine content from it without putting your own system at risk.
After going through this, I’ll see what I can do to put some bows on some of the devel-only packages and get them into CRAN so there’s a bit more assurance around using them.
I’m an army of one when it comes to fielding R-related security issues, but if you do come across suspicious items (like this or icky/malicious in other ways) don’t hesitate to drop me an @ or DM on Twitter.




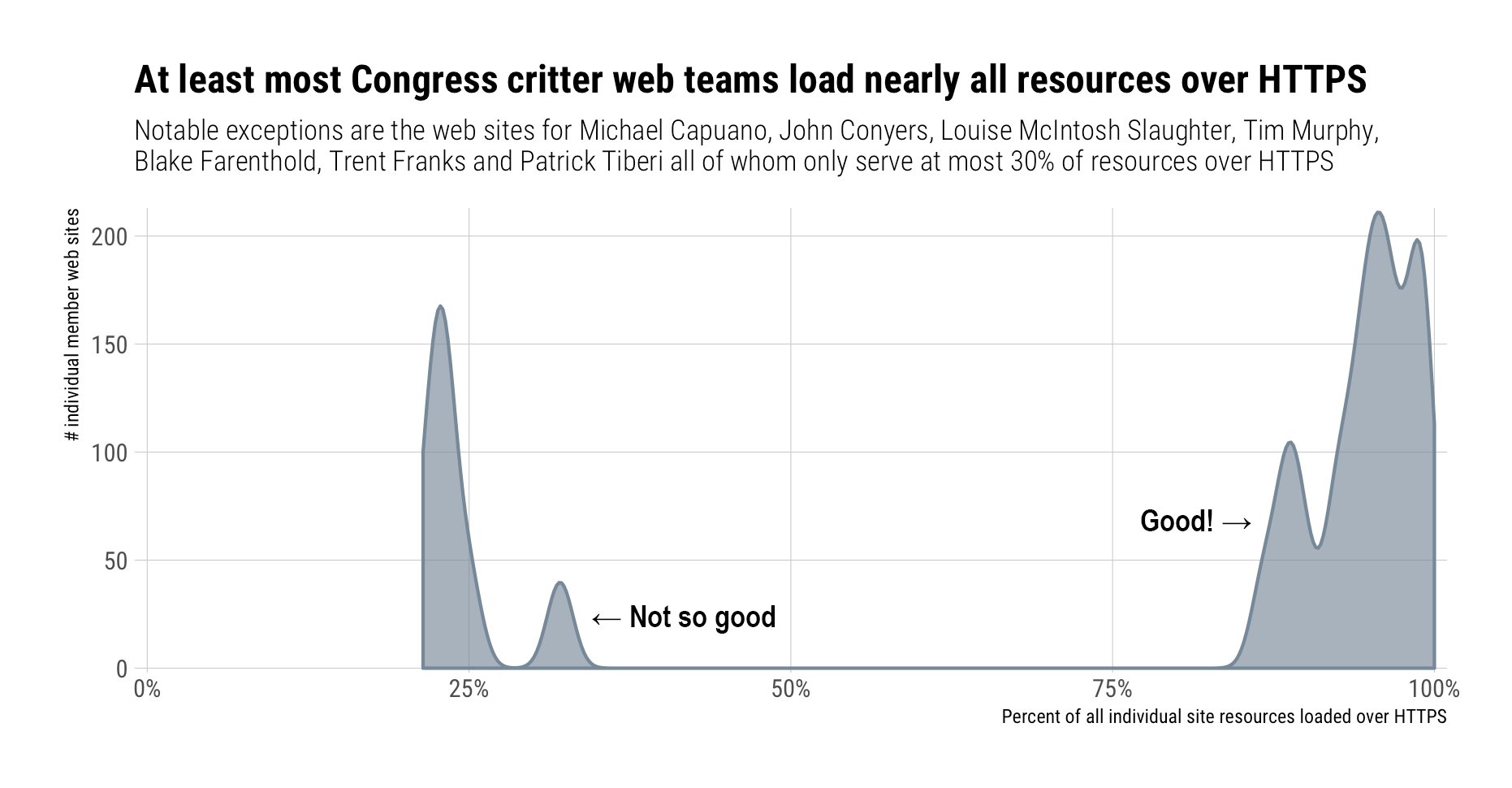














A Word About Tracking On This Site
Since I just railed against Congress for being a bit two-faced about privacy I thought some
rud.issite disclosure would be in order.At present, third-party tracking is limited to:
fonts.googleapis.com. There are a few more other DNS pre-fetches that I’m also going to try to eradicate (but that aren’t showing up in my uBlock Origin likely to to/etc/hostsblocks);The above came from an in-browser uBlock Origin report.
I ran a
splashr::render_har()— which is how I measured things for the Congressional privacy post — on one of my pages and this is the result:Props on WordPress capturing
w.org! I’m still ticked Microsoft stolebob.comfrom me ages ago.As you can see, most resources load from my site and none come from Twitter, Facebook or Google Plus.
I run WordPress for a ton of reasons too long to go into for this post, so I’m likely not going to change anything about that list (apart from the DNS pre-fetching).
Hopefully that will abate any concerns visitors might have, especially after reading the post about Congress.