I apologize up-front for using bad words in this post.
Said bad words include “Facebook”, “Mark Zuckerberg” and many referrals to entities within the U.S. Government. Given the topic, it cannot be helped.
I’ve also left the R tag on this despite only showing some ggplot2 plots and Markdown tables. See the end of the post for how to get access to the code & data. R was used solely and extensively for the work behind the words.
This week Congress put on a show as they summoned the current Facebook CEO — Mark Zuckerberg — down to Washington, D.C. to demonstrate how little most of them know about how the modern internet and social networks actually work plus chest-thump to prove to their constituents they really and truly care about you.
These Congress-critters offered such proof in the guise of railing against Facebook for how they’ve handled your data. Note that I should really say our data since they do have an extensive profile database on me and most everyone else even if they’re not Facebook platform users (full disclosure: I do not have a Facebook account).
Ostensibly, this data-mishandling impacted your privacy. Most of the committee members wanted any constituent viewers to come away believing they and their fellow Congress-critters truly care about your privacy.
Fortunately, we have a few ways to measure this “caring” and the remainder of this post will explore how much members of the U.S. House and Senate care about your privacy when you visit their official .gov web sites. Future posts may explore campaign web sites and other metrics, but what better place to show they care about you then right there in their digital houses.
Privacy Primer
When you visit a web site with any browser, the main URL pulls in resources to aid in the composition and functionality of the page. These could be:
- HTML (the main page is very likely HTML unless it’s just a media URL)
- images (
png, jpg, gif, “svg”, etc),
- fonts
- CSS (the “style sheet” that tells the browser how to decorate and position elements on the page)
- binary objects (such as embedded PDF files or “protocol buffer” content)
- XML or JSON
- JavaScript
(plus some others)
When you go to, say, www.example.com the site does not have to load all the resources from example.com domains. In fact, it’s rare to find a modern site which does not use resources from one or more third party sites.
When each resource is loaded (generally) some information about you goes along for the ride. At a minimum, the request time and source (your) IP address is exposed and — unless you’re really careful/paranoid — the referring site, browser configuration and even cookies are even available to the third party sites. It does not take many of these data points to (pretty much) uniquely identify you. And, this is just for “benign” content like images. We’ll get to JavaScript in a bit.
As you move along the web, these third-party touch-points add up. To demonstrate this, I did my best to de-privatize my browser and OS configuration and visited 12 web sites while keeping a fresh install of Firefox Lightbeam running. Here’s the result:

Each main circle is a distinct/main site and the triangles are resources the site tried to load. The red triangles indicate a common third-party resource that was loaded by two or more sites. Each of those red triangles knows where you’ve been (again, unless you’ve been very careful/paranoid) and can use that information to enhance their knowledge about you.
It gets a bit worse with JavaScript content since a much stronger fingerprint can be created for you (you can learn more about fingerprints at this spiffy EFF site). Plus, JavaScript code can try to pilfer cookies, “hack” the browser, serve up malicious adverts, measure time-on-site, and even enlist you in a cryptomining army.
There are other issues with trusting loaded browser content, but we’ll cover that a bit further into the investigation.
Measuring “Caring”
The word “privacy” was used over 100 times each day by both Zuckerberg and our Congress-critters. Senators and House members made it pretty clear Facebook should care more about your privacy. Implicit in said posit is that they, themselves, must care about your privacy. I’m sure they’ll be glad to point out all along the midterm campaign trails just how much they’re doing to protect your privacy.
We don’t just have to take their word for it. After berating Facebook’s chief college dropout and chastising the largest social network on the planet we can see just how much of “you” these representatives give to Facebook (and other sites) and also how much they protect you when you decide to pay them[†] [‡] a digital visit.
For this metrics experiment, I built a crawler using R and my splashr? package which, in turn, uses ScrapingHub’s open source Splash. Splash is an automation framework that lets you programmatically visit a site just like a human would with a real browser.
Normally when one scrapes content from the internet they’re just grabbing the plain, single HTML file that is at the target of a URL. Splash lets us behave like a browser and capture all the resources — images, CSS, fonts, JavaScript — the site loads and will also execute any JavaScript, so it will also capture resources each script may itself load.
By capturing the entire browser experience for the main page of each member of Congress we can get a pretty good idea of just how much each one cares about your digital privacy, and just how much they secretly love Facebook.
Let’s take a look, first, at where you go when you digitally visit a Congress-critter.
Network/Hosting/DNS
Each House and Senate member has an official (not campaign) site that is hosted on a .gov domain and served up from a handful of IP addresses across the following (n is the number of Congress-critter web sites):
| asn |
aso |
n |
| AS5511 |
Orange |
425 |
| AS7016 |
Comcast Cable Communications, LLC |
95 |
| AS20940 |
Akamai International B.V. |
13 |
| AS1999 |
U.S. House of Representatives |
6 |
| AS7843 |
Time Warner Cable Internet LLC |
1 |
| AS16625 |
Akamai Technologies, Inc. |
1 |
“Orange” is really Akamai and Akamai is a giant content delivery network which helps web sites efficiently provide content to your browser and can offer Denial of Service (DoS) protection. Most sites are behind Akamai, which means you “touch” Akamai every time you visit the site. They know you were there, but I know a sufficient body of folks who work at Akamai and I’m fairly certain they’re not too evil. Virtually no representative solely uses House/Senate infrastructure, but this is almost a necessity given how easy it is to take down a site with a DoS attack and how polarized politics is in America.
To get to those IP addresses, DNS names like www.king.senate.gov (one of the Senators from my state) needs to be translated to IP addresses. DNS queries are also data gold mines and everyone from your ISP to the DNS server that knows the name-to-IP mapping likely sees your IP address. Here are the DNS servers that serve up the directory lookups for all of the House and Senate domains:
| nameserver |
gov_hosted |
| e4776.g.akamaiedge.net. |
FALSE |
| wc.house.gov.edgekey.net. |
FALSE |
| e509.b.akamaiedge.net. |
FALSE |
| evsan2.senate.gov.edgekey.net. |
FALSE |
| e485.b.akamaiedge.net. |
FALSE |
| evsan1.senate.gov.edgekey.net. |
FALSE |
| e483.g.akamaiedge.net. |
FALSE |
| evsan3.senate.gov.edgekey.net. |
FALSE |
| wwwhdv1.house.gov. |
TRUE |
| firesideweb02cc.house.gov. |
TRUE |
| firesideweb01cc.house.gov. |
TRUE |
| firesideweb03cc.house.gov. |
TRUE |
| dchouse01cc.house.gov. |
TRUE |
| c3pocc.house.gov. |
TRUE |
| ceweb.house.gov. |
TRUE |
| wwwd2-cdn.house.gov. |
TRUE |
| 45press.house.gov. |
TRUE |
| gopweb1a.house.gov. |
TRUE |
| eleven11web.house.gov. |
TRUE |
| frontierweb.house.gov. |
TRUE |
| primitivesocialweb.house.gov. |
TRUE |
Akamai kinda does need to serve up DNS for the sites they host, so this list also makes sense. But, you’ve now had two touch-points logged and we haven’t even loaded a single web page yet.
Safe? & Secure? Connections
When we finally make a connection to a Congress-critter’s site, it is going to be over SSL/TLS. They all support it (which is ?, but SSL/TLS confidentiality is not as bullet-proof as many “HTTPS Everywhere” proponents would like to con you into believing). However, I took a look at the SSL certificates for House and Senate sites. Here’s a sampling from, again, my state (one House representative):

The *.house.gov “Common Name (CN)” is a wildcard certificate. Many SSL certificates have just one valid CN, but it’s also possible to list alternate, valid “alt” names that can all use the same, single certificate. Wildcard certificates ease the burden of administration but it also means that if, say, I managed to get my hands on the certificate chain and private key file, I could setup vladimirputin.house.gov somewhere and your browser would think it’s A-OK. Granted, there are far more Representatives than there are Senators and their tenure length is pretty erratic these days, so I can sort of forgive them for taking the easy route, but I also in no way, shape or form believe they protect those chains and private keys well.
In contrast, the Senate can and does embed the alt-names:

Are We There Yet?
We’ve got the IP address of the site and established a “secure” connection. Now it’s time to grab the index page and all the rest of the resources that come along for the ride. As noted in the Privacy Primer (above), the loading of third-party resources is problematic from a privacy (and security) perspective. Just how many third party resources do House and Senate member sites rely on?
To figure that out, I tallied up all of the non-.gov resources loaded by each web site and plotted the distribution of House and Senate (separately) in a “beeswarm” plot with a boxplot shadowing underneath so you can make out the pertinent quantiles:

As noted, the median is around 30 for both House and Senate member sites. In other words, they value your browsing privacy so little that most Congress-critters gladly share your browser session with many other sites.
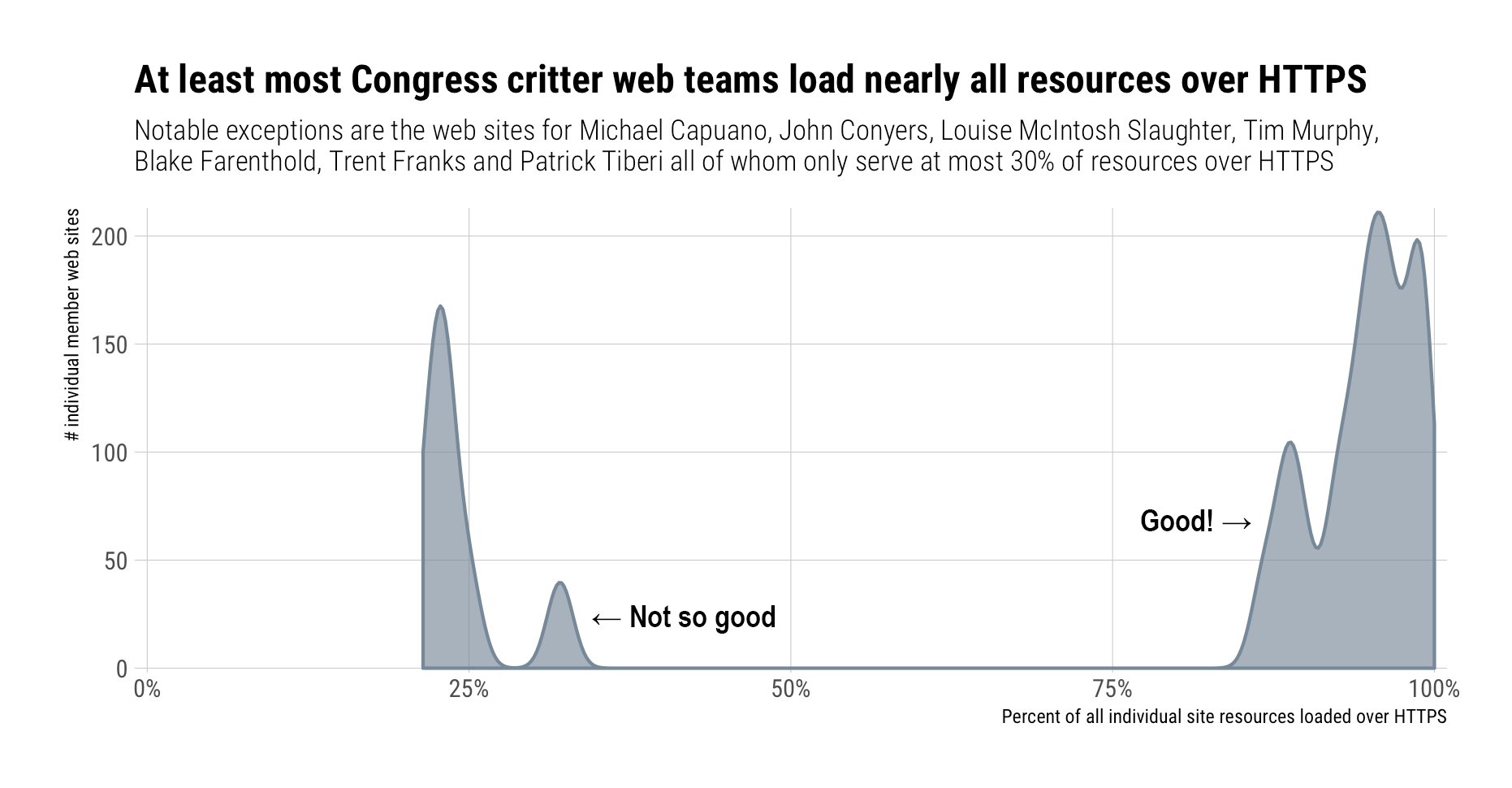
We also talked about confidentiality above. If an https site loads http resources the contents of what you see on the page cannot but guaranteed. So, how responsible are they when it comes to at least ensuring these third-party resources are loaded over https?

You’re mostly covered from a pseudo-confidentiality perspective, but what are they serving up to you? Here’s a summary of the MIME types being delivered to you:
| MIME Type |
Number of Resources Loaded |
| image/jpeg |
6,445 |
| image/png |
3,512 |
| text/html |
2,850 |
| text/css |
1,830 |
| image/gif |
1,518 |
| text/javascript |
1,512 |
| font/ttf |
1,266 |
| video/mp4 |
974 |
| application/json |
673 |
| application/javascript |
670 |
| application/x-javascript |
353 |
| application/octet-stream |
187 |
| application/font-woff2 |
99 |
| image/bmp |
44 |
| image/svg+xml |
39 |
| text/plain |
33 |
| application/xml |
15 |
| image/jpeg, video/mp2t |
12 |
| application/x-protobuf |
9 |
| binary/octet-stream |
5 |
| font/woff |
4 |
| image/jpg |
4 |
| application/font-woff |
2 |
| application/vnd.google.gdata.error+xml |
1 |
We’ll cover some of these in more detail a bit further into the post.
Facebook & “Friends”
Facebook started all this, so just how cozy are these Congress-critters with Facebook?

Turns out that both Senators and House members are very comfortable letting you give Facebook a love-tap when you come visit their sites since over 60% of House and 40% of Senate sites use 2 or more Facebook resources. Not all Facebook resources are created equal[ly evil] and we’ll look at some of the more invasive ones soon.
Facebook is not the only devil out there. I added in the public filter list from Disconnect and the numbers go up from 60% to 70% for the House and from 40% to 60% for the Senate when it comes to a larger corpus of known tracking sites/resources.
Here’s a list of some (first 20) of the top domains (with one of Twitter’s media-serving domains taking the individual top-spot):
| Main third-party domain |
# of ‘pings’ |
% |
| twimg.com |
764 |
13.7% |
| fbcdn.net |
655 |
11.8% |
| twitter.com |
573 |
10.3% |
| google-analytics.com |
489 |
8.8% |
| doubleclick.net |
462 |
8.3% |
| facebook.com |
451 |
8.1% |
| gstatic.com |
385 |
6.9% |
| fonts.googleapis.com |
270 |
4.9% |
| youtube.com |
246 |
4.4% |
| google.com |
183 |
3.3% |
| maps.googleapis.com |
144 |
2.6% |
| webtrendslive.com |
95 |
1.7% |
| instagram.com |
75 |
1.3% |
| bootstrapcdn.com |
68 |
1.2% |
| cdninstagram.com |
63 |
1.1% |
| fonts.net |
51 |
0.9% |
| ajax.googleapis.com |
50 |
0.9% |
| staticflickr.com |
34 |
0.6% |
| translate.googleapis.com |
34 |
0.6% |
| sharethis.com |
32 |
0.6% |
So, when you go to check out what your representative is ‘officially’ up to, you’re being served…up on a silver platter to a plethora of sites where you are the product.
It’s starting to look like Congress-folk aren’t as sincere about your privacy as they may have led us all to believe this week.
A [Java]Script for Success[ful Privacy Destruction]
As stated earlier, not all third-party content is created equally malicious. JavaScript resources run code in your browser on your device and while there are limits to what it can do, those limits diminish weekly as crafty coders figure out more ways to use JavaScript to collect information and perform shady or malicious deeds.
So, how many House/Senate sites load one or more third-party JavaScript resources?

Virtually all of them.
To make matters worse, no .gov or third-party resource of any kind was loaded using subresource integrity validation. Subresource integrity validation means that the site owner — at some point — ensured that the resource being loaded was not malicious and then created a fingerprint for it and told your browser what that fingerprint is so it can compare it to what got loaded. If the fingerprints don’t match, the content is not loaded/executed. Using subresource integrity is not trivial since it requires a top-notch content management team and failure to synchronize/checkpoint third-party content fingerprints will result in resources failing to load.
Congress was quick to demand that Facebook implement stronger policies and controls, but they, themselves, cannot be bothered.
Future Work
There are plenty more avenues to explore in this data set (such as “security headers” — they all 100% use strict-transport-security pretty well, but are deeply deficient in others) and more targets for future works, such as the campaign sites of House and Senate members. I may follow up with a look at a specific slice from this data set (the members of the committees who were berating Zuckerberg this week).
The bottom line is that while the beating Facebook took this week was just, those inflicting the pain have a long way to go themselves before they can truly judge what other social media and general internet sites do when it comes to ensuring the safety and privacy of their visitors.
In other words, “Legislator, regulate thyself” before thy regulatists others.
FIN
Apart from some egregiously bad (or benign) examples, I tried not to “name and shame”. I also won’t answer any questions about facets by party since that really doesn’t matter too much as they’re all pretty bad when it comes to understanding and implementing privacy and safey on their sites.
The data set can be found over at Zenodo (alternately, click/tap/select the badge below). I converted the R data frame to ndjson/streaming JSON/jsonlines (however you refer to the format) and tested it out in Apache Drill.
I’ll toss up some R code using data extracts later this week (meaning by April 20th).








GDPR Unintended Consequences Part 1 — Increasing WordPress Blog Exposure
I pen this mini-tome on “GDPR Enforcement Day”. The spirit of GDPR is great, but it’s just going to be another Potempkin Village in most organizations much like PCI or SOX. For now, the only thing GDPR has done is made GDPR consulting companies rich, increased the use of javascript on web sites so they can pop-up useless banners we keep telling users not to click on and increase the size of email messages to include mandatory postscripts (that should really be at the beginning of the message, but, hey, faux privacy is faux privacy).
Those are just a few of the “unintended consequences” of GDPR. Just like Let’s Encrypt & “HTTPS Everywhere” turned into “Let’s Enable Criminals and Hurt Real People With Successful Phishing Attacks”, GDPR is going to cause a great deal of downstream issues that either the designers never thought of or decided — in their infinite, superior wisdom — were completely acceptable to make themselves feel better.
Today’s installment of “GDPR Unintended Consequences” is WordPress.
WordPress “powers” a substantial part of the internet. As such, it is a perma-target of attackers.
Since the GDPR Intelligentsia provided a far-too-long lead-time on both the inaugural and mandated enforcement dates for GDPR and also created far more confusion with the regulations than clarity, WordPress owners are flocking to “single button install” solutions to make them magically GDPR compliant (
#protipthat’s not “a thing”). Here’s a short list of plugins and active installation counts (no links since I’m not going to encourage attack surface expansion):I’m somewhat confident that a fraction of those publishers follow secure coding guidelines (it may be a small fraction). But, if I was an attacker, I’d be poking pretty hard at a few of those with six-figure installs to see if I could find a usable exploit.
GDPR just gave attackers a huge footprint of homogeneous resources to attempt at-scale exploits. They will very likely succeed (over-and-over-and-over again). This means that GDPR just increased the likelihood of losing your data privacy…the complete opposite of the intent of the regulation.
There are more unintended consequences and I’ll pepper the blog with them as the year and pain progresses.